SarcDetect: Sarcasm detection with transfer learning
15 Sep 2018 | I am not sarcastic!ULMFiT is a great technique for applying transfer learning in nlp. It has shown to achieve great results with small amounts of data. So, when I came across the SemEval2018 task for irony detection, I wanted to put it to the test.
Table of Contents
Usually in nlp, we use word embeddings, which are vectors of floats that represent different words. But in ULMFiT, we use a pretrained language model and fine-tune it for our task. A language model not only has word embeddings, but has also been trained to get a representation of full sentences and documents.
Pre-processing
We clean up the data a little. Remove user-mentions, links and numbers from the tweet. Also, I separated the hashes to better obtain their co-relation with the tweet Here is the code I used:
from nltk.tokenize import TweetTokenizer
import re
import wordsegment as ws
ws.load()
def preprocess(tweet):
tknzr = TweetTokenizer(reduce_len=True, strip_handles=True)
tokens = tknzr.tokenize(tweet)
tweet = " ".join(tokens) # we need to ensure that all the tokens are separated using the space
tweet = tweet.lower()
tweet = re.sub(r'http[s]?://(?:[a-z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-f][0-9a-f]))+', '', tweet) # URLs
tweet = re.sub(r'(?:@[\w_]+)', '', tweet) # user-mentions
tweet = re.sub(r'(?:\#+[\w_]+[\w\'_\-]*[\w_]+)', '', tweet) # hashtags
tweet = re.sub(r'(?:(?:\d+,?)+(?:\.?\d+)?)', '', tweet) # numbers
return tweet
def segmentHashes(tweet):
tags = " ".join(re.findall(r"#(\w+)", tweet))
return " ".join(ws.segment(tags)).lower()
Preparing the data
Let’s get the training, validation and test data into the necessary format. We split the data 70-30 for validation
from fastai.text import *
from sklearn.model_selection import train_test_split
import wordsegment as ws
path = ''
ws.load()
df = pd.read_csv(path + 'SemEval2018-Task3-master/datasets/train/SemEval2018-T3-train-taskB_emoji_ironyHashtags.txt', delimiter='\t')
df['hashes'] = df.apply(lambda row: segmentHashes(row['Tweet text']), axis=1)
df['Tweet text'] = df.apply(lambda row: preprocess(row['Tweet text']), axis=1)
train_df, valid_df = train_test_split(df, test_size=0.7)
test_df = pd.read_csv(path + 'SemEval2018-Task3-master/datasets/goldtest_TaskB/SemEval2018-T3_gold_test_taskB_emoji.txt', delimiter='\t')
test_df['hashes'] = test_df.apply(lambda row: segmentHashes(row['Tweet text']), axis=1)
test_df['Tweet text'] = test_df.apply(lambda row: preprocess(row['Tweet text']), axis=1)

Building our classifier
Fine-tune the language model
We first get a pre-trained model to use as our base. Since we are classifying English tweets, the WT103 model (from fastai) works fine for our case. Fine-tuning it for tweets is as simple as:
# Language model data
data_lm = TextLMDataBunch.from_df(
path = 'salil',
train_df = train_df,
valid_df = valid_df,
test_df = test_df,
label_cols = ['Label'],
text_cols = ['Tweet text', 'hashes']
)
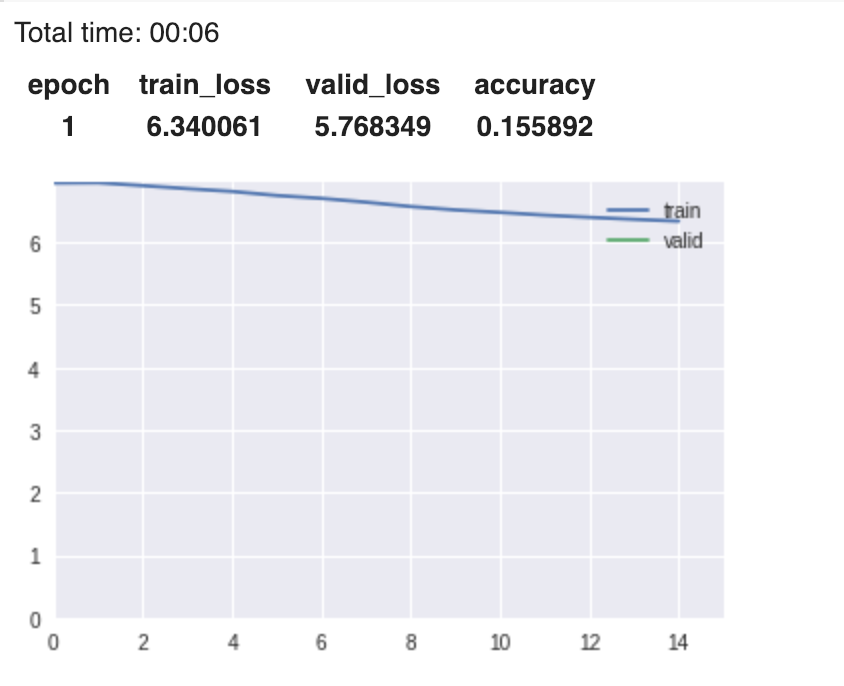
learn = language_model_learner(data_lm, pretrained_model=URLs.WT103_1, drop_mult=0.7, callback_fns=ShowGraph)
learn.fit_one_cycle(1, 1e-2)
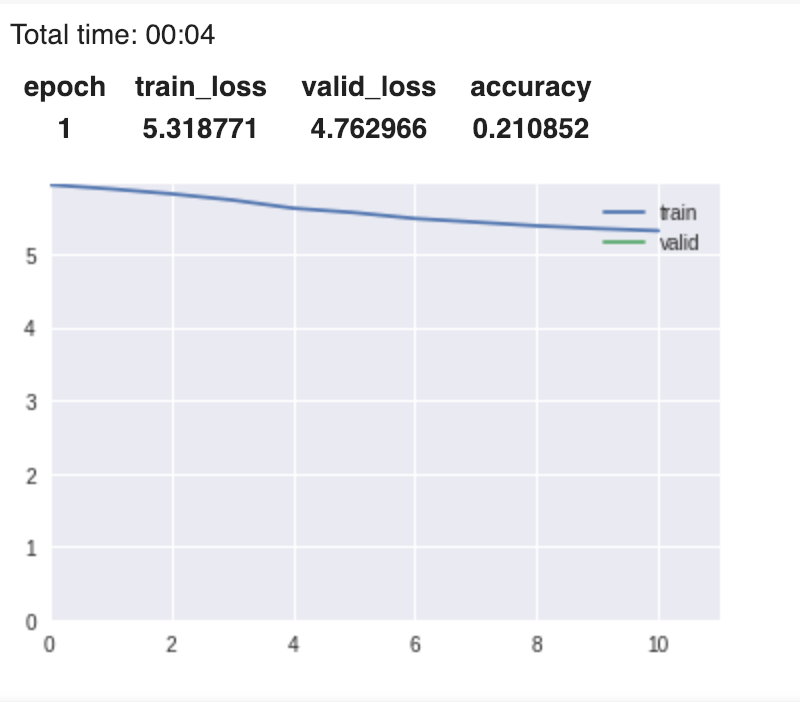
We unfreeze the model and fine-tune it:
learn.unfreeze()
learn.fit_one_cycle(1, 1e-3)
We can test our language model by having it create some tweets for us:

Fine-tune for classification
Now, we fine-tune it for the purpose of classification.
learn = text_classifier_learner(data_clas, drop_mult=0.5)
learn.load_encoder('tweet_enc')
learn.fit_one_cycle(1, 1e-2)
learn.freeze_to(-2)
learn.fit_one_cycle(1, slice(5e-3/2., 5e-3))
learn.unfreeze()
learn.fit_one_cycle(1, slice(2e-3/100, 2e-3))
The classifier is tuned and ready to classify.
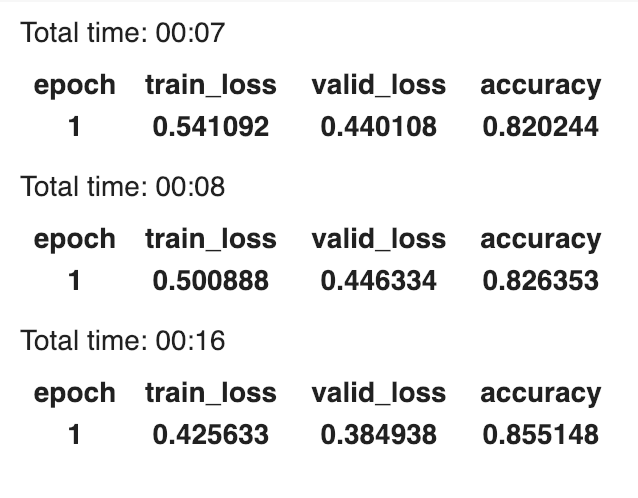
Results
Without much work, we easily got an accuracy of around 85% on the validation set